KI, kaum eine Abkürzung hat in der letzten Zeit solche Wellen geschlagen wie die der künstlichen Intelligenz. Zurückzuführen ist dieser raketenhafte Aufschwung wohl auf ChatGPT, ein Sprachmodell, das natürliche Sprache verstehen und generieren kann. Ende 2022 veröffentlichte OpenAI die chatbot-ähnliche Plattform, die schon nach wenigen Tagen Millionen von Nutzern akquirieren konnte. Aber wie genau funktioniert ChatGPT eigentlich hinter den Kulissen oder, viel allgemeiner, wie funktionieren Sprachmodelle?
In der vielseitigen Landschaft des sogenannten Machine- und Deep Learnings, was umgangssprachlich als KI bezeichnet wird, genießen vor allem Sprachmodelle öffentliches Aufsehen. Vereinfacht gesprochen stellen diese Modelle eine Art Software dar, die wiederkehrende Muster in natürlicher Sprache erkennen kann. Besagte Muster spiegeln dabei Zusammenhänge wie „Taxi = Auto“ oder „Ente = Vogel“ wider und helfen dem Modell, die jeweilige Sprache im Allgemeinen zu verstehen.
Tatsächlich ist das erwähnte Sprachverständnis einem Sprachmodell nicht in die Wiege gelegt. Erst in einem komplexen und rechenaufwändigen Trainingsprozess lernt ein Sprachmodell, die diversen Muster einer Sprache zu registrieren. Zu diesem Zweck werden dem Modell in der Trainingsphase schrittweise unterschiedliche Textsequenzen gezeigt, wie:
–>Auf dem Parkplatz stehen Autos, beispielsweise Busse und Taxis.
–>Am Ufer sitzen Enten und andere Vögel.
–>Es war einmal eine Prinzessin mit sehr langem und blondem Haar.
Wörter wie „Auto“, „Taxi“ und „Bus“ treten in den Sequenzen häufig zusammen auf, oder auf Ausdrücke wie „Es war einmal“ folgen wiederholt Wörter wie „Prinzessin“ oder „König“. Betrachtet ein Modell auf diese Weise Millionen von Textsequenzen, so erhält es die Fähigkeit, die Sprache mitsamt ihren mannigfaltigen Zusammenhänge zu überblicken. Mittlerweile hat dieser Prozess ein Ausmaß erreicht, bei dem beispielsweise zum Training der Sprachmodelle von OpenAI signifikante Bestandteile des Internets als Quelle für die Textsequenzen verwendet werden [1], [2].
Basierend auf dem erlangten Sprachverständnis ist ein Sprachmodell in der Lage, unterschiedlichste Aufgaben zu bewältigen, wobei insbesondere die Generierung von neuen Texten zunehmend an Popularität gewinnt. Hierbei erzeugt ein Sprachmodell auf Grundlage einer Eingabe, beispielsweise einer Aufgabenbeschreibung, einen eigenen Text. Der Generierungsprozess verläuft dabei wahrscheinlichkeitsbasiert. Schritt für Schritt wählt das Modell jeweils das wahrscheinlichste Wort basierend auf dem bereits generierten Text und der Eingabe aus. In Anbetracht des Sprachverständnisses wird so der Ausdruck „es war einmal eine“ wahrscheinlich eher mit dem Wort „Prinzessin“ als mit dem Wort „Ente“ ergänzt.
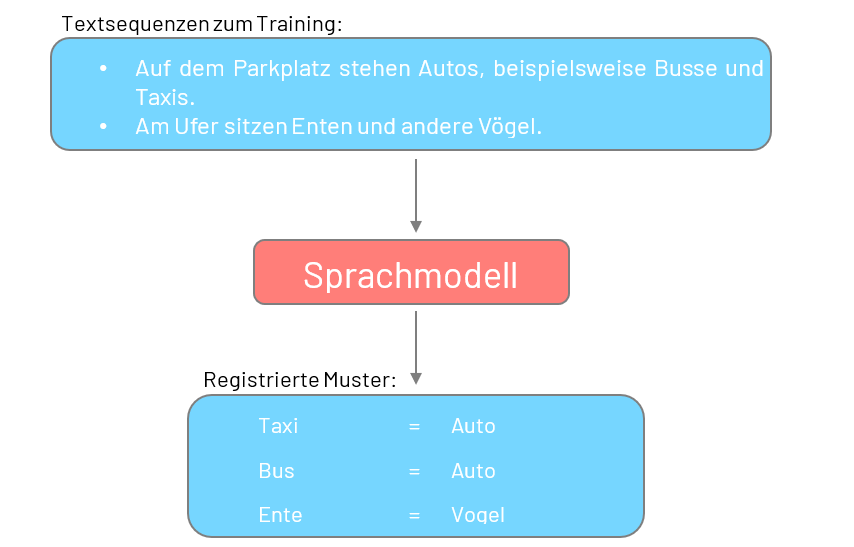
Abb. Abstrakte Darstellung des Trainingsprozesses eines Sprachmodells
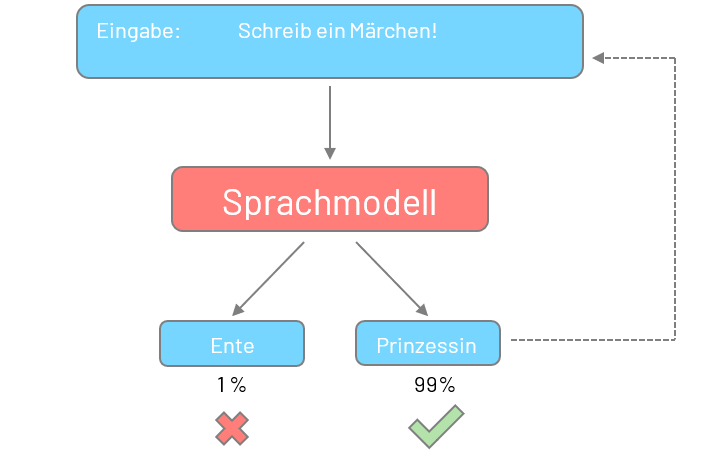
Abb. Generierung von Text auf Basis einer Eingabe
Unglücklicherweise erzeugt ein Sprachmodell nicht garantiert ein richtiges Ergebnis. Vielmehr wird das wahrscheinlichste Ergebnis generiert, was sich unter Berücksichtigung der Eingabe und der zum Training verwendeten Textsequenzen ergibt. Was insbesondere für unterstützende Assistenzsysteme, in welchen der Mensch stets die Chance zum Intervenieren hat und in unkritischen Domänen völlig ausreichend ist, birgt jedoch bei der Automatisierung von Prozessen Risiken.
Beim Entwickeln von sprachmodellbasierten Anwendungen muss diese inhärente Beschränkung stets berücksichtigt werden. So wird im Rahmen von PAL beispielsweise die Strategie verfolgt, eine Google-ähnliche Suche von firmeninternen Dokumenten zu realisieren, die auf konventionellen Algorithmen basiert und diese mit Sprachmodellen verknüpft, um eine natürlichsprachliche Antwort auf eine Frage zu erhalten. Da keine Garantie bezüglich der Richtigkeit der vom Sprachmodell generierten Antwort gegeben werden kann, bieten die von den Algorithmen zurückgelieferten, für die Frage relevanten Dokumente dem Nutzenden die Möglichkeit zur manuellen Überprüfung. Auf diese Weise werden die Fähigkeiten eines Sprachmodells vorteilhaft eingesetzt und gleichzeitig die Risiken minimiert.
[1] – Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Ben- jamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. NeurIPS, 2020
[2] – Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer, 2019.
Erfahren Sie mehr zum Praxisprojekt 8